Concepts
This section discusses concepts one should understand about the SCR library implementation including how it interacts with file systems. Terms defined here are used throughout the documentation.
Jobs, allocations, and runs
A long-running application often must be restarted multiple times in order to execute to completion. It may be interrupted due to a failure, or it may be interrupted due to time limits imposed by the resource manager. To make forward progress despite such interruptions, an application saves checkpoints during its earlier executions that are used to restart the application in later executions. We refer to this sequence of dependent executions and its checkpoint history as an SCR job or simply a job.
Each execution requires resources that have been granted by the resource manager. We use the term allocation to refer to an assigned set of compute resources that are available to the user for a period of time. A resource manager typically assigns an identifier label to each resource allocation, which we refer to as the allocation id. SCR embeds the allocation id in some directory and file names.
Within an allocation, a user may execute an application one or more times.
We call each execution a run.
For MPI applications, each run corresponds to a single invocation
of mpirun or its equivalent.
Note that the term job has different meanings depending on its context. In addition to referring to a sequence of dependent runs, we sometimes use the term job to refer to an individual allocation or run that contributes to such a sequence.
Furthermore, the term job has different definitions in the context of resource managers and MPI applications. For example, a SLURM job corresponds to what we refer to as an “allocation”, and an MPI job corresponds to what we refer to as a “run”. We define the terms allocation and run to help distinguish between those different meanings. However, we may also use the term job when the context is clear.
Group, store, and redundancy descriptors
The SCR library must group processes of the parallel job in various ways. For example, if power supply failures are common, it is necessary to identify the set of processes that share a power supply. Similarly, it is necessary to identify all processes that can access a given storage device, such as an SSD mounted on a compute node. To represent these groups, the SCR library uses a group descriptor. Details of group descriptors are given in Group, store, and checkpoint descriptors.
Each group is given a unique name.
The library creates two groups by default: NODE and WORLD.
The NODE group consists of all processes on the same compute node,
and WORLD consists of all processes in the run.
One can define additional groups via configuration files (see Configure a job).
The SCR library must also track details about each class of storage it can access. For each available storage class, SCR needs to know the associated directory prefix, the group of processes that share a device, the capacity of the device, and other details like whether the associated file system can support directories. SCR tracks this information in a store descriptor. Each store descriptor refers to a group descriptor, which specifies how processes are grouped with respect to that class of storage. For a given storage class, it is assumed that all compute nodes refer to the class using the same directory prefix. Each store descriptor is referenced by its directory prefix.
The library creates one store descriptor by default: /dev/shm.
The assumption is made that /dev/shm is mounted as a local file system
on each compute node.
On Linux clusters, /dev/shm is typically tmpfs (RAM disk),
which implements a file system using main memory as the backing storage.
Additional store descriptors can be defined in configuration files (see Configure a job).
Finally, SCR defines redundancy descriptors to associate a redundancy scheme with a class of storage devices and a group of processes that are likely to fail at the same time. It also tracks details about the particular redundancy scheme used, and the frequency with which it should be applied. Redundancy descriptors reference both store and group descriptors.
The library defines a default redundancy descriptor.
It assumes that processes on the same node are likely to fail at the same time
(compute node failure).
It also assumes that datasets can be cached in /dev/shm,
which is assumed to be storage local to each compute node.
It applies an XOR redundancy scheme using a group size of 8.
Additional redundancy descriptors may be defined in configuration files (see Configure a job).
Control, cache, and prefix directories
SCR manages numerous files and directories to cache datasets and to record its internal state. There are three fundamental types of directories: control, cache, and prefix directories. For a detailed illustration of how these files and directories are arranged, see the example presented in Example of SCR files and directories.
The control directory is where SCR writes files to store its internal state about the current run. This directory is expected to be stored in node-local storage. SCR writes multiple, small files in the control directory, and it accesses these files frequently. It is best to configure this directory to be in node-local RAM disk.
To construct the full path of the control directory, SCR incorporates a control base directory name along with the user name and allocation id associated with the resource allocation. This enables multiple users, or multiple jobs by the same user, to run at the same time without conflicting for the same control directory. A default control base directory is hard-coded into the SCR library at configure time, but this value may be overridden at runtime.
SCR can direct the application to write dataset files to subdirectories within a cache directory. SCR also stores its redundancy data in these subdirectories. The storage that hosts the cache directory must be large enough to hold the data for one or more datasets plus the associated redundancy data. Multiple cache directories may be utilized in the same run, which enables SCR to use more than one class of storage within a run (e.g., RAM disk and SSD). Cache directories should ideally be located on scalable storage.
To construct the full path of a cache directory, SCR incorporates a cache base directory name with the user name and the allocation id associated with the resource allocation. It is valid for a cache directory to use the same base path as the control directory. A default cache base directory is hard-coded into the SCR library at configure time, but this value may be overridden at runtime.
The user must configure the maximum number of datasets that SCR should keep in each cache directory. It is up to the user to ensure that the capacity of the device associated with the cache directory is large enough to hold the specified number of datasets.
SCR refers to each application checkpoint or output set as a dataset. SCR assigns a unique sequence number to each dataset called the dataset id. It assigns dataset ids starting from 1 and counts up with each successive dataset written by the application. Within a cache directory, a dataset is written to its own subdirectory called the dataset directory.
Finally, the prefix directory is a directory on the parallel file system that the user specifies. SCR copies datasets to the prefix directory for permanent storage (see Fetch, flush, and scavenge). The prefix directory should be accessible from all compute nodes, and the user must ensure that the prefix directory is unique for each job. For each dataset stored in the prefix directory, SCR creates and manages a dataset directory. The dataset directory holds all SCR redundancy files and meta data associated with a particular dataset. SCR maintains an index file within the prefix directory, which records information about each dataset stored there.
Note that the term “dataset directory” is overloaded. In some cases, we use this term to refer to a directory in cache and in other cases we use the term to refer to a directory within the prefix directory on the parallel file system. In any particular case, the meaning should be clear from the context.
Example of SCR files and directories
To illustrate how files and directories are arranged in SCR,
consider the example shown in Figure Example SCR directories.
In this example, a user named user1
runs a 3-task MPI job with one task per compute node.
The base directory for the control directory is /dev/shm,
the base directory for the cache directory is /ssd,
and the prefix directory is /pscratch/user1/simulation123.
The control and cache directories are storage devices local to the compute node.
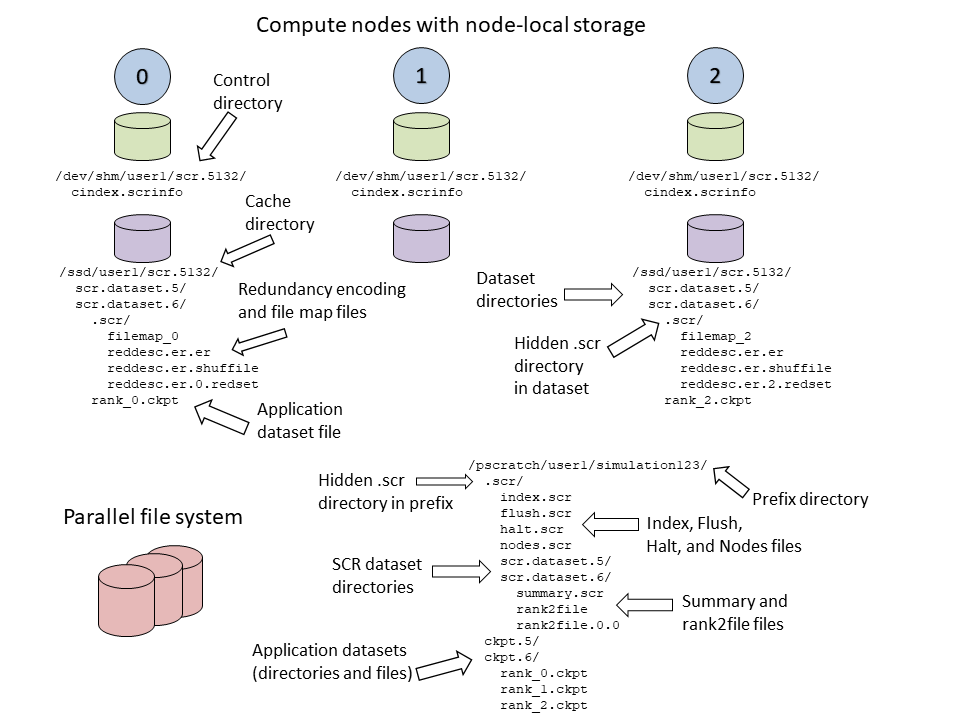
Example SCR directories
The full path of the control directory is /dev/shm/user1/scr.5132.
This is derived from the concatenation of the control base directory /dev/shm,
the user name user1, and the allocation id 5132.
SCR keeps files to persist its internal state in the control directory,
including a cindex.scrinfo file as shown.
Similarly, the cache directory is /ssd/user1/scr.5132,
which is derived from the concatenation of the cache base directory /ssd,
the user name user1, and the allocation id 5132.
Within the cache directory, SCR creates a subdirectory for each dataset.
In this example, there are two datasets with ids 5 and 6.
The application dataset files and SCR redundancy files
are stored within their corresponding dataset directory.
On the node running MPI rank 0,
there is one application dataset file rank_0.ckpt,
and numerous SCR metadata files in a hidden .scr subdirectory.
The full path of the prefix directory is /pscratch/user1/simulation123.
This is a path on the parallel file system that is specified by the user.
It is unique to the particular simulation the user is running simulation123.
The prefix directory contains a hidden .scr directory where SCR writes
its index.scr file to record info for each of the datasets (see Manage datasets).
The SCR library writes other files to this hidden directory,
including the halt.scr file (see Halt a job).
Within the .scr directory, SCR also creates a directory
for each dataset named scr.dataset.<id> where <id> is the dataset id.
SCR stores metadata files that are specific to the dataset in these dataset directories
including summary.scr and rank2file files along with redundancy files.
Application files for each dataset are written to their original path within the prefix directory
as the application specified during its call to SCR_Route_file.
In this example, the application stores all files for a particular dataset within its own subdirectory.
There are directories named ckpt.5 and ckpt.6 corresponding to two datasets.
The files from all processes for each dataset are contained within its respective ckpt directory.
Application file names and directory paths can be arbitrary so long as all items are placed within
the prefix directory and item names in each dataset are distinct from names in other datasets.
Redundancy schemes
In practice, it is common for multiple processes to fail at the same time, but most often this happens because those processes depend on a single, failed component. It is not common for multiple, independent components to fail simultaneously. By expressing the groups of processes that are likely to fail at the same time, the SCR library can apply redundancy schemes to withstand common, multi-process failures. We refer to a set of processes likely to fail at the same time as a failure group.
SCR must also know which groups of processes share a given storage device. This is useful so the group can coordinate its actions when accessing the device. For instance, if a common directory must be created before each process writes a file, a single process can create the directory and then notify the others. We refer to a set of processes that share a storage device as a storage group.
SCR defines default failure and storage groups, and if needed, additional groups can be defined in configuration files (see Group, store, and checkpoint descriptors). Given definitions of failure and storage groups, the SCR library implements four redundancy schemes which trade off performance, storage space, and reliability:
Single- Each dataset file is written to storage accessible to the local process.Partner- Each dataset file is written to storage accessible to the local process, and a full copy of each file is written to storage accessible to a partner process from another failure group.XOR- Each dataset file is written to storage accessible to the local process, XOR parity data are computed from dataset files of a set of processes from different failure groups, and the parity data are stored among the set.RS- Each dataset file is written to storage accessible to the local process, and Reed-Solomon encoding data are computed from dataset files of a set of processes from different failure groups, and the encoding data are stored among the set.
With Single, SCR writes each dataset file in storage accessible to the local process.
It requires sufficient space to store the maximum dataset file size.
This scheme is fast, but it cannot withstand failures that disable the storage device.
For instance, when using node-local storage,
this scheme cannot withstand failures that disable the node,
such as when a node loses power or its network connection.
However, it can withstand failures that kill the application processes
but leave the node intact, such as application bugs and file I/O errors.
With Partner, SCR writes dataset files to storage accessible to the local process,
and it also copies each dataset file to storage accessible to a partner process
from another failure group.
This scheme is slower than Single, and it requires twice the storage space.
However, it is capable of withstanding failures that disable a storage device.
In fact, it can withstand failures of multiple devices,
so long as a device and the corresponding partner device that holds the copy
do not fail simultaneously.
With XOR, SCR defines sets of processes
where members within a set are selected from different failure groups.
The processes within a set collectively compute XOR parity data which are
stored in files along side the application dataset files.
This algorithm is based on the work found in [Gropp],
which in turn was inspired by RAID5 [Patterson].
The XOR scheme can withstand multiple failures so long as
two processes from the same set do not fail simultaneously.
Computationally, XOR is more expensive than Partner, but it requires less storage space.
Whereas Partner must store two full dataset files,
XOR stores one full dataset file plus one XOR parity segment,
where the segment size is roughly \(1/(N-1)\) times the size of
a dataset file for a set of size \(N\).
Although XOR requires more computation,
it can be be faster than Partner when storage bandwidth
is a performance bottleneck since XOR writes less data.
With RS, like XOR, SCR defines sets of processes
where members within a set are selected from different failure groups.
The processes within a set collectively compute Reed-Solomon encoding data which are
stored in files along side the application dataset files.
The RS scheme can require more computation and storage space than XOR,
but it can tolerate up to a configurable number of \(k\) failures per set,
where \(1 <= k < N\).
The RS encoding data scales as \(k/(N-k)\)
times the size of a dataset file for a given value \(k\) and a set of size \(N\).
By default, RS can recover up to \(k = 2\) failures per set.
For both XOR and RS, larger sets require less storage,
but they also increase the probability that a given set
will suffer multiple failures simultaneously.
Larger sets may also increase the cost of recovering files in the event of a failure.
The set size \(N\) can be adjusted with the SCR_SET_SIZE parameter.
The number of failures \(k\) can be adjusted with the SCR_SET_FAILURES parameter.
Redundancy scheme |
Storage requirements per process |
Maximum failures per set |
|---|---|---|
|
\(B\) |
\(0\) |
|
\(B * 2\) |
\(1+\) |
|
\(B * N / (N - 1)\) |
\(1\) |
|
\(B * N / (N - k)\) |
\(k\) where \(1 <= k < N\) |
“A Case for Redundant Arrays of Inexpensive Disks (RAID)”, D. Patterson, G. Gibson, and R. Katz, Proc. of 1988 ACM SIGMOD Conf. on Management of Data, 1988, http://web.mit.edu/6.033/2015/wwwdocs/papers/Patterson88.pdf.
“Providing Efficient I/O Redundancy in MPI Environments”, William Gropp, Robert Ross, and Neill Miller, Lecture Notes in Computer Science, 3241:7786, September 2004. 11th European PVM/MPI Users Group Meeting, 2004, http://www.mcs.anl.gov/papers/P1178.pdf.
Scalable restart
So long as a failure does not violate the redundancy scheme, a job can restart within the same resource allocation using a cached checkpoint. This saves the cost of writing checkpoint files out to the parallel file system only to read them back during the restart. In addition, SCR provides support for the use of spare nodes. A job can allocate more nodes than it needs and use the extra nodes to fill in for any failed nodes during a restart. The process of restarting a job from a cached checkpoint is referred to as a scalable restart. SCR includes a set of scripts which encode much of the scalable restart logic (see Run a job).
Upon encountering a failure,
SCR relies on the MPI library, the resource manager, or some other external service
to kill the current run.
After the run is killed,
and if there are sufficient healthy nodes remaining,
the same job can be restarted within the same allocation.
In practice, such a restart typically amounts to issuing another
mpirun in the job batch script.
Of the set of nodes used by the previous run, the restarted run should try to use as many of the same nodes as it can to maximize the number of files available in cache. A given MPI rank in the restarted run does not need to run on the same node that it ran on in the previous run. SCR distributes cached files among processes according to the process mapping of the restarted run.
By default, SCR inspects the cache for existing checkpoints when a run starts. It attempts to rebuild all datasets in cache, and then it attempts to restart the job from the most recent checkpoint. If a dataset fails to rebuild, SCR deletes it from cache.
An example restart scenario is illustrated in Figure Scalable restart
in which a 4-node job using the Partner scheme allocates 5 nodes
and successfully restarts within the allocation after a node fails.
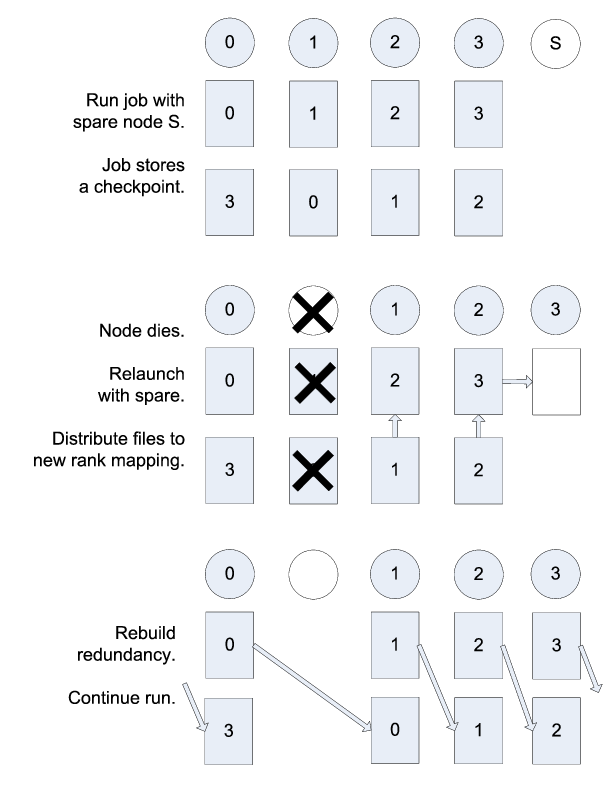
Example restart after a failed node with Partner
Catastrophic failures
There are some failures from which the SCR library cannot recover a cached checkpoint. In such cases, SCR falls back to the most recent checkpoint written to the parallel file system. Such failures are called catastrophic failures, and they include the following examples:
Multiple node failure which violates the redundancy scheme. If multiple nodes fail in a pattern which violates the cache redundancy scheme, data are irretrievably lost.
Failure during a checkpoint. Due to cache size limitations, some applications can only fit one checkpoint in cache at a time. For such cases, a failure may occur after the library has deleted the previous checkpoint but before the next checkpoint has completed. In this case, there is no valid checkpoint in cache to recover.
Failure of the node running the job batch script. The logic at the end of the allocation to scavenge the latest checkpoint from cache to the parallel file system executes as part of the job batch script. If the node executing this script fails, the scavenge logic will not execute and the allocation will terminate without copying the latest checkpoint to the parallel file system.
Parallel file system outage. If the application fails when writing output due to an outage of the parallel file system, the scavenge logic may also fail when it attempts to copy files to the parallel file system.
There are other catastrophic failure cases not listed here.
Checkpoints must be written to the parallel file system with some moderate frequency so as not to lose too much work in the event of a catastrophic failure. Section Fetch, flush, and scavenge provides details on how to configure SCR to make occasional writes to the parallel file system.
By default, the current implementation stores only the most recent checkpoint in cache.
One can change the number of checkpoints stored in cache by setting
the SCR_CACHE_SIZE parameter.
If space is available, it is recommended to increase this value to at least 2.
Fetch, flush, and scavenge
SCR manages the transfer of datasets between the prefix directory on the parallel file system and the cache. We use the term fetch to refer to the action of copying a dataset from the parallel file system to cache. When transferring data from cache to the parallel file system, there are two terms used: flush and scavenge. Under normal circumstances, the library directly copies files from cache to the parallel file system, and this direct transfer is known as a flush. However, sometimes a run is killed before the library can complete this transfer. In these cases, a set of SCR commands is executed after the final run to ensure that the latest checkpoint and any output datasets are copied to the parallel file system before the allocation expires. We say that these scripts scavenge those datasets.
Each time an SCR job starts, SCR first inspects the cache and attempts to rebuild files for a scalable restart as discussed in Scalable restart. If the cache is empty or the rebuild fails, SCR attempts to load a checkpoint from the prefix directory. SCR reads the index file and attempts to load the checkpoint that is marked as current. If no checkpoint is designated as current, SCR attempts to load the most recent checkpoint. When restarting from a checkpoint, SCR records whether the restart attempt succeeds or fails in the index file. SCR does not attempt to load a checkpoint that is marked as being incomplete nor does SCR attempt to load a checkpoint for which a previous restart attempt has failed. If SCR attempts but fails to load a checkpoint, it prints an error and it will attempt to load the next most recent checkpoint if one is available.
By default, SCR fetches the checkpoint into cache and applies a redundancy scheme.
This is useful on systems where failures are likely,
since SCR may be able to restart the application from the cached checkpoint
if the application fails before it writes its next checkpoint.
One can configure SCR to avoid copying the checkpoint to
cache by setting the SCR_FETCH_BYPASS parameter to 0.
This may provide for faster restart when reading from the cache is slow.
An application may elect not to use SCR for restart.
In this case, one should set the SCR_FETCH parameter to 0.
If the fetch is disabled, the application is responsible for
identifying and reading its checkpoint.
To withstand catastrophic failures,
it is necessary to write checkpoints out to the parallel file system with some moderate frequency.
In the current implementation,
the SCR library writes a checkpoint out to the parallel file system after every 10 checkpoints.
This frequency can be configured by setting the SCR_FLUSH parameter.
When this parameter is set, SCR decrements a counter with each successful checkpoint.
When the counter hits 0, SCR writes the current checkpoint out to the file system and resets the counter
to the value specified in SCR_FLUSH.
SCR can preserve this counter between restarts
such that it is possible to maintain periodic checkpoint writes across runs.
Set SCR_FLUSH to 0 to disable periodic writes in SCR.
If an application disables the periodic flush feature,
the application is responsible for writing occasional checkpoints to the parallel file system.